
經過系列文第一篇《提昇Google搜尋排名的SEO,原來一直都被我們錯用了》的解說,相信大家都對開始SEO之前最最重要的一步有點想法了,接下來就來到了「根據你目的而生」的實際做法---爬蟲篇,一起來了解吧!
Crawling,也就是讓搜尋引擎(Search Engine)找得到你!
搜尋引擎找網頁的方式有幾種,但主要是透過程式,或所謂的爬蟲(Crawler)。從信賴度高、流量高的網站開始抓網頁上的超連結(hyperlink),然後從這些連結的網頁再繼續抓上面的超連結,這的步驟不斷往下往外繼續擴張。Google會把這些超連結都記錄起來,像一個網狀圖一樣,網址A連到網址B, 網址C, 網址D類似的方式,然後把這個網狀關係以及每個連結的網頁內容,儲存到資料庫裡。
這是非常重要的一步,如果爬蟲連你的網頁都找不到,搜尋引擎是無法把你的網站或網頁放進它的索引(Index)。對新網站來說,最快讓搜尋引擎找到你的方式就是到Google的網站管理者工具註冊你的網站。搜尋引擎會根據你網站的大小,隱定性跟重要程度去決定多久爬一次你的網頁。

什麼是Crawl Budget? 量有差嗎?
當一個網站的網頁量很大的時候,像是電商型(eCommerce)商品量龐大的網站來說,伺服器(Server)回應的速度效能,容易影響爬蟲下載網頁的量跟下次光臨的時間。這是所謂民間流傳Crawl Budget的問題。大部份網站不太會有Crawl Budget,也就是說只要是你網站沒像eBay這麼大,還夠穩,不會常常出現錯誤指令(time out or server error),或是一大堆404 Error、其他錯誤,幾乎爬蟲會爬所有找得到的網頁。
針對這個階段,建議大家
(1) 經常查看Webmaster/Search Console裡的crawl errors, response time,並且比對logs看搜尋引擎爬蟲流量是否穩定。
(2) 時常測試重要的網頁,比如說熱門商品網頁(Top Products)或是你希望使用者在Google搜尋結果裡搜得到的頁面,是否能讓爬蟲順利打開。如果你的網頁內容是java script產生,或是有user agent detection,可以在Search Console用’Fetch as Google’,或者下載User Agent Switcher看搜尋引擎所看到的網頁內容是否跟預期的一樣。你給Googlebot看的內容必須跟給一般使用者看的內容沒有差別,不然的話會有掛羊頭賣狗肉(Cloaking)之嫌,網頁極有可能被取消索引,光想到這裡都覺得悲慘無比。
到底爬蟲都爬哪些網頁(Crawl Mix)
不同URL但內容大同小異
如果兩個以上的URL都呈現很相似甚至一樣的內容,這些URL可能會相互競爭(cannibalize) ranking,因為搜尋引擎不知道要選哪一個; 例如說:
- www.widgets.com/blue-widgets?color=blue 跟 www.widgets.com/blue-widgets 重複
- www.widgets.com/blue-widgets?color=blue&cat=3 跟www.widgets.com/blue-widgets?cat=3&color=blue 重複
建議把產生網址(URL)的邏輯標準化,同一個內容的網頁只會有一條對應網址。如果你網站設計的原因造成類似以上的URL情況,建議使用 canonical tag 把這些網頁都串連起來,讓搜尋引擎知道哪個URL版本是你希望出現在搜尋結果頁面裡。
內容更新的程度、速度(Staleness)?
搜尋引擎喜歡「時常更新的內容(fresh content)」,如果你重要的網頁常常更新,建議注意爬蟲光臨的頻率,如果爬蟲爬的頻率跟內容更新頻率差很遠,有可能會發生(A)搜尋引擎不覺得這些網頁重要(B)它很難從首頁連到這些網頁。
使用者會搜尋這些網頁嗎(Importance)?
最好讓重要的網頁從首頁3個點擊(Clicks)以內就可以連到。如果一個網頁很難從首頁連得到,搜尋引擎很可能解讀這個網頁「不重要」。建議時常分析爬蟲爬的網頁裡面,多少百分比是你認為重要的網頁。如果你發現這個百分比很小,頻率也很低,而且爬蟲花時間在不重要的網頁居多,你可能得再調整你網站的架構了; 扁化你的網站(flatten your site),讓重要的網頁往上移。
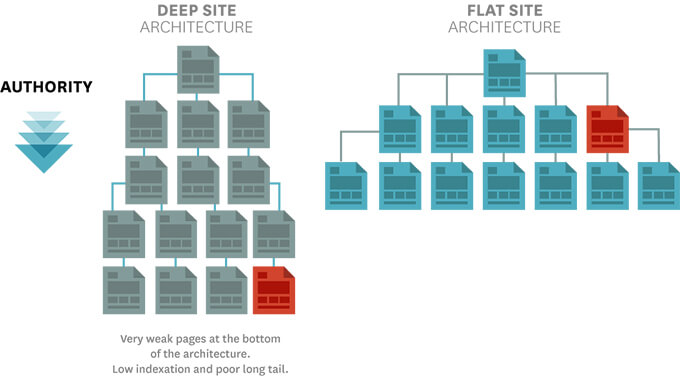
(Source https://goo.gl/FdKrT1)
一般來說,並不是每個網頁都值得被爬,甚至放進索引(Index),像是電商網站的結帳頁(check out)或是我的帳戶(my account這種網頁,大多是需要使用者登入或有隱私資訊,所以對搜尋引擎的有用度很低。你可以透過no nidex tag或是 Robots.txt讓爬蟲少來爬。
好處是,爬蟲不會浪費時間在無意義的網頁上,壞處有些重要的網頁,有可能會因為某個網頁誤標成不要爬,就因此消失在爬蟲的雷達當中。
XML Sitemap又是什麼,有多重要?
另一個讓爬蟲一次爬你重要的方式就是XML Sitemap。把所有你認為是很重要的網頁提交給Google,並且建議多久來爬一次,甚至每個網頁有多重要(數字從0到1)。雖然這兩個資訊被Google搜尋引擎大佬John Mueller否認有任何重要性,但放這些資訊在XML Sitemap裡是沒有什麼壞處的。
簡單來說,crawling是最重要的一步,如果爬蟲找不到你的網頁,使用者就無法從Google找到你。這邊要注意的是
(1)清楚計畫你怎麼讓爬蟲找到你,你可以透過GSC註冊,外部連結(從大網站像Google+, YouTube, YellowPages連到你網站),點擊付費廣告Paid Search等等快速的方式
(2) 把你希望使用者能從Google找到的網頁放到XML Sitemap,並且在GSC提交
(3) 從自家的伺服器紀錄(server logs)比對哪些網頁被Google的爬蟲爬過,狀態碼(status code)是什麼,爬蟲到底花時間在哪些網頁上,重要還是不重要的網頁,有哪些網頁從來沒被爬過的,去慢慢調整你網站的內部連結。
就是現在,跟著這篇內容一步一步地執行,讓Google更認識你的網站,最後提高SEO的呈現和排名。
也推薦妳看看
《PM、行銷、設計的共通基礎角色:成為一位好的「用戶研究員」》
獨家精選只在LINE裡頭,現在先▸▸ ![]() 接著回傳「有興趣的內容(例如PM、行銷、海外工作、Slash人才、家居、穿搭)」讓我們遞給妳最相關的第一手消息!
接著回傳「有興趣的內容(例如PM、行銷、海外工作、Slash人才、家居、穿搭)」讓我們遞給妳最相關的第一手消息!
如果你也想透過「一對一」的方式,和蓋洛普優勢認證教練即時討論,深入挖掘自己的優勢,解決目前的職涯問題 ►前往了解如何預約「一對一職涯優勢諮詢」
〖一對一學員回饋〗
「走在認識自己的路上,我一直認真懇切地想明白『我』到底是什麼樣的人,蓋洛普優勢測驗就是我找到的其中一項工具。」

也推薦你看看:
若你正在工作中遇到瓶頸...有些小卡關... ▶︎點擊看更多 BetweenGos 職涯服務
職場不是一個人的戰鬥,讓我們陪你把職涯走得更順利🌿一天一點靈感,獻給知性的你!歡迎追蹤我們的 IG 給你更多美好提案:)